karl_karlsson

Silver Member | Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору
Braintank
Цитата:| Больно уж странная у вас аналогия выходит: пирога на самом деле является маленький круизный лайнер, а лайнер, своего рода, большая пирога. Нет, ну можно и так на эти вещи смотреть, но мне сложно оперировать подобными аргументами. |
На самом деле супер компьютеры и являются большие калькуляторы - их назначение только вычислять. А внутри калькулятора и есть одночиповый компьютер.
Цитата:| Для меня как для человека, имеющего за плечами свыше 10 лет в типографском деле (допечатная подготовка) это звучит просто смешно и в комментариях не нуждается. Не зная законов языка ирокезского… |
Ну напротив. Оптические размеры кириллических шрифтов где имеются в компьютерной типографией? Кернинг кириллицы у западных кириллических шрифтов? А что об верстки математики вне TeX? Такие вопросы очень многие. Но то что мне очевидным является - русские книги естественных наук в компьютерной эры уже не те что делали прежде вручную.
Цитата:| Не знаю, как там у многих людей, но у меня он работает без проблем и ошибок. У коллег (каллек выношу за скобки) также. |
Сюда имеется ввиду не только hardware, но компьютер как единое целое. Если hardware и хорошо сделали (хотя на сегодня и это не уже как было), то у программах масса багов и недостатков. Не говоря о затрате времени их поиска и тестирования. Еще обновления версии т.д.
Цитата:| На нём чего-то и сделали. Причём несопоставимо лучше, практичнее и экономичнее. |
То что много - конечно, это машина. Но не всегда и везде лучше. Где то практичнее. Экономичнее - никак. Электричество и сами компьютеры из ничего не образуются. Их промышленность не лучше и не экономнее бумажной. То, что сделали некоторые вещи бесспорным и является. Но это не так много, как кажется на первый взгляд.
Цитата: + стотыщпицод.
Только один момент интересен: ладно, такое утверждение справедливо в отношении Microsoft Office, но хромает на обе ноги уже применительно к Adobe Creative Suite. Именно потому, что если в первом случае мы большинство состоит из прокладок между стулом и клавиатурой, которым интеллект моллюска не позволяет толком освоить даже текстовый редактор (соответственно, и спрашивать с продавца некому), то в последнем случае большинство вменяемо, профпригодно и, более того, занято своим прямым делом.
И в нашем случае, что я уже не раз подчёркивал, ну хотя бы 40 % искателей предмета разговора разве нельзя отнести к людям, с полным правом носящим паспорт, а не просто к биомассе-электрату? Или я чересчур оптимистичен в своих оценках? |
Значит, я думаю вот так. Сначала системы DTP (Desktop publishing), к которым например InDesign из Adobe Creative Suite причисляется, были доступны и пользовались только в основном для технической документации и т.п. Например FrameMaker так и начался. И это было то что определяло. А вот на сегодня какие то рекламные брошюры и так далее. Ну и чтобы было дешевле Adobe поручает разработку всяких разных сторонних компании. Только посмотрите окно About. Всем хочется быстро и дешево, несмотря размером и качества...
Мне даже хочется Adobe Reader полностью поменять, но пока невозможно.
Цитата:| Я, наверное, слишком невежествен, потому что высокий полёт вашей мысли стремится где-то очень уж высоко над моей скромной головой. Я честно старался, но так и не понял, какое отношение написанное имеет к редакторам с древовидной структурой (не говоря уже о конечной задаче — выявлению хотя бы одного, пригодного для использования по назначению). |
Скорее всего русский у меня не очень. Отношение такое - надо иметь постановку задачи. Но иногда сама задача меняется в ходу поиска ее решения. Это и называется процесс. Вы меняете структуру и одновременным образом ее пополняете. Но размер структуры небольшой иначе ее менять сложно. Это и являются редакторы с древовидной структурой. Если вы пополняете готовую структуру - это и есть база данных. Это как у вас структуры уже есть.
Цитата: Попробую пояснить, но прежде попутно замечу,что в рассуждениях на такую тему хотелось бы видеть сочетание двух вещей: элементарного представления о предмете разговора со способностью внятно и грамотно излагать свою мысль при наличии таковой (ладно, 2,5 вещи получилось).
Теперь ответы:
Да, это 200 МБ только текста.
HTML по определению представляет собой тот же только текст.
TreePad+ очень разумно и удобно хранит текстовую составляющую БД в одном файле, а всю графическую — в другом, представляющем собой обычный архив ZIP. Причём первый файл — также тупо текстовый.
Другое дело, что и в 2012 году, как и в незапамятном 2003 (когда вышел TreePad 6.5) текст записуль, цитат, выдержек и прочего в программе, в принципе не понимающей Юникода, хранится в формате RTF!!! (Те, кому и в самом деле нужно то, что мы тут обсуждаем, меня поняли.) Для мыслящего существа, у которого адресное пространство никак не укладывается в семиразрядный ASCII, даже при проживании в техасской глубинке набрать таким способом 200 мегабайт — как два пальца об асфальт. |
Ну это проблема архитектуры. У HTML-а интерпретация неоднозначная. Имеются некоторые "стандарты", которые непрестанным образом меняют, и которых браузеры следуют кто как захочет даже если у них багов нет. У TeX стандарты твердые и замороженные, кроме того все баги практически давним давно отловлены. Но TeX интерактивным не является. Компиляция для больших документов проходить намного медленнее реального времени. 200 МБ TeX-овских исходниках равняются где то не менее PDF-а 20 000 страниц. Ну такие большие книги иногда и пишут. Но думаю, не каждый из техасской глубинке...
Цитата:| В основном так происходит у лиц родом из племён, практикующих культ карго. Персонально у меня (и доподлинно знаю, что не у меня одного), HTML происходит в равной степени как на серверах, так и браузере, нескольких текстовых редакторах, агрегаторе вебстраниц, лебедевском «Реформаторе»… может, ещё где, навскидку вспомнил только это. |
Я не то имел ввиду. Статическая схема генерации HTML хорошо масштабируемый объект не является. Все что является большое использует динамической генерации - серверный язык (как PHP, Perl, Python и т.д.) и базу данных (MySQL, MSSQL и т.д.). Вот подумайте, если захотите поменять оформлением у статического проекта насчитывающего 200 МБ HTML. Например поменять цвет 20 000 тегов H1?
Таким образом разделяют содержанием и его представлением.
Цитата:| Как-то замечательно обхожусь виртуальными серверами, материальная часть которых расположена то ли в России, то ли в Голландии. Да, а что касательно до software, то выше я в спешке позабыл упомянуть обычный файловый менеджер FreeCommander 2009.02b, запускаемый c флешдиска. Прикиньте, у меня ведь и в нём HTML происходит, когда я дисковый файл обрабатываю и почему-то не хочу открывать его в браузере… |
Usbwebserver таким же образом и запускается. Думаю, запустить базу MySQL в нескольких десятков ГБ не будет проблема. Например база библиотеки LibGen уже порядка 1 ГБ и работает без проблем.
Цитата:| Да прямо! Вы и обосновать сие в состоянии? |
MySQL, MSSQL и подобных баз на этого и делаются и соответвующим образом тестируются и применяются. У них на сегодня и сотни ТБ не проблема.
Или запросто HTML + картинок - это файловая система NTFS такая же "база данных". Наименее нескольких миллиард файлов проблемой не являются.
А то, что все другое не идет - опыт, как и сами заметили на примере TreePad+, подтверждает.
Цитата:| Таааким способом?!?! Теперь рассуждения по поводу HTML перестали меня удивлять. |
Ну а каким способом? Дерево на HTML не сделаете. Надо еще и JavaScript. Проверять его на 5-6 основных браузерах плюс 10-20 версии у каждого кто будет?
Цитата:| Такие объёмы собирают, как общее правило, не пользователи, а криворукие и жопоголовые быдлокодеры. Разумеется, если кодировать текст в RTF (сам ни разу не программист, но насколько могу судить по косвенным признакам, именно так и поступает 80 % творцов предмета нашего разговора), а чтобы не показалось мало, ещё и разукрашивать его напрямую, всячески поощряя к этому пользователя (который и сам, кстати сказать, вышел из той же шинели), собрать монструозный файл можно за год. Как раз достаточное время, чтобы с пользователем случился vendor block. Экий мне бином Ньютона: достаточно слово офис заносить в файл в нотации \'ee\'f4\'e8\'f1… |
Это конечно так.
Цитата:| Не поверите, но именно с целью выборки из семантизированного массива необходимых мыслящему пользователю многокритериальных, не поддающихся однозначному определению знаний. Моя почившая во Бозе база данных, скажем, состояла сугубо из словарей по разным дисциплинам. Это при том, что чудовищного размера Большая Советская Энциклопедия вместе со всеми иллюстрациями живёхонько себе работает в качестве одного из полутысячи словарей в моей ABBYY Lingvo x3. И как только оно всё без сервера и MySQL обходится — просто уму непостижимо… |
У ABBYY своя база данных. Возможно, если спросите в технической поддержки, что то ответят.
Сами ABBYY не какие то обычные. FineReader не случайным образом является OCR номер 1. У него достаточно серьезные (притом уникальные) математические алгоритмы. И это так сказать передовая математика. У больших баз данных то же самое - немалая и непростая математика внутри работает (ну и работала на проектированием). Не все, что кажется тривиальным таким и является. |











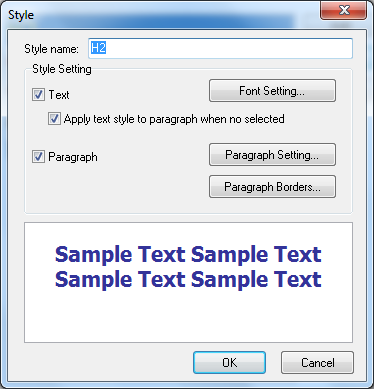
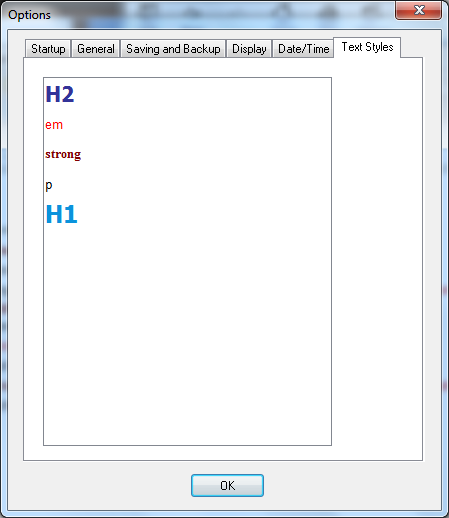
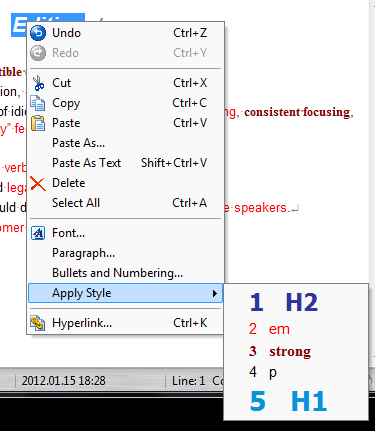
 Какое удобство, а? И нафига? Ладно бы к этим номерам хотя бы клавиатурные сочетания привязаны были, так ведь нет…
Какое удобство, а? И нафига? Ладно бы к этим номерам хотя бы клавиатурные сочетания привязаны были, так ведь нет… 








 это всё…
это всё…